Projects
How to train your EBM without Markov Chain Monte Carlo
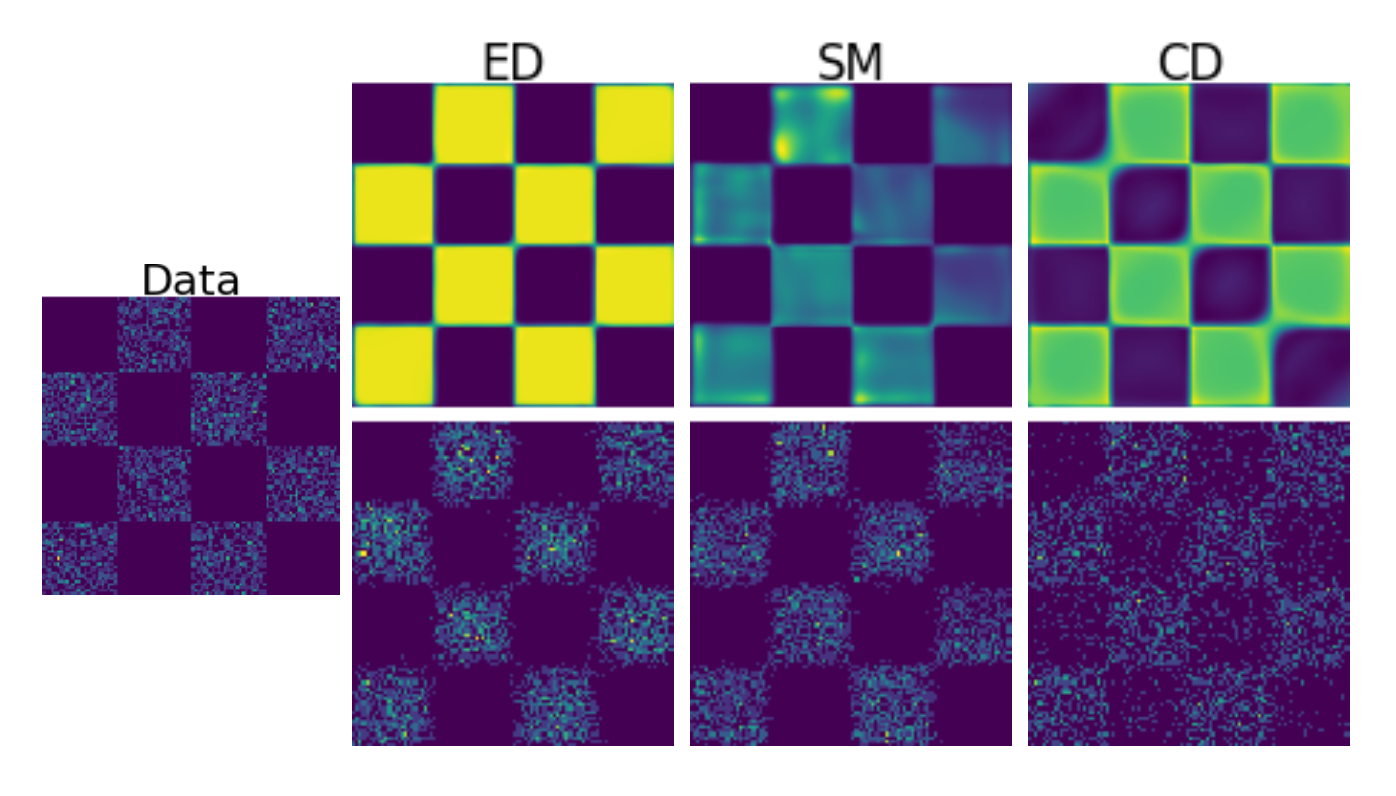
We propose a new training methodology for energy-based models based on Energy Discrepancy (ED) which does not rely on sampling (like contrastive divergence, short CD) or Stein scores (as in score-based methods, short SM). The goal are robust unbiased models for high-dimensional data. Our paper “Energy Discrepancies: A Score-Independent Loss for Energy-Based Models” can be accessed here. An extension to energy-based models on discrete spaces has been presented at the ICML 2023 workshop Sampling and Optimisation in Discrete Spaces and can be found here
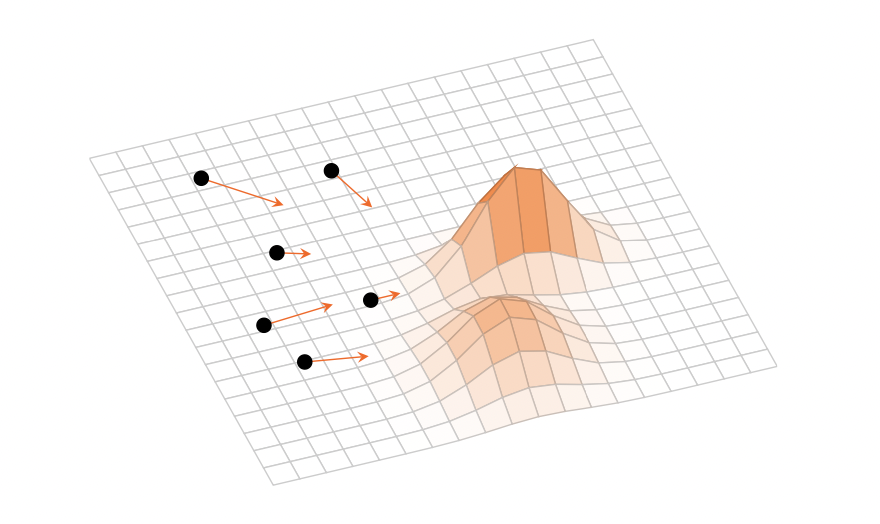
Variational Inference as a gradient flow in a kernelised Wasserstein geometry
Variational Inference optimises a training objective with gradient descent to infer optimal parameters in a parametric family of distributions, for example, to compute an approximate Bayesian posterior distribution. For my Master thesis, I formulated the training dynamics as a gradient flow in a kernelised Wasserstein geometry based on the results on Stein geometries and a relationship between gradient flows and black box variational inference