Projects
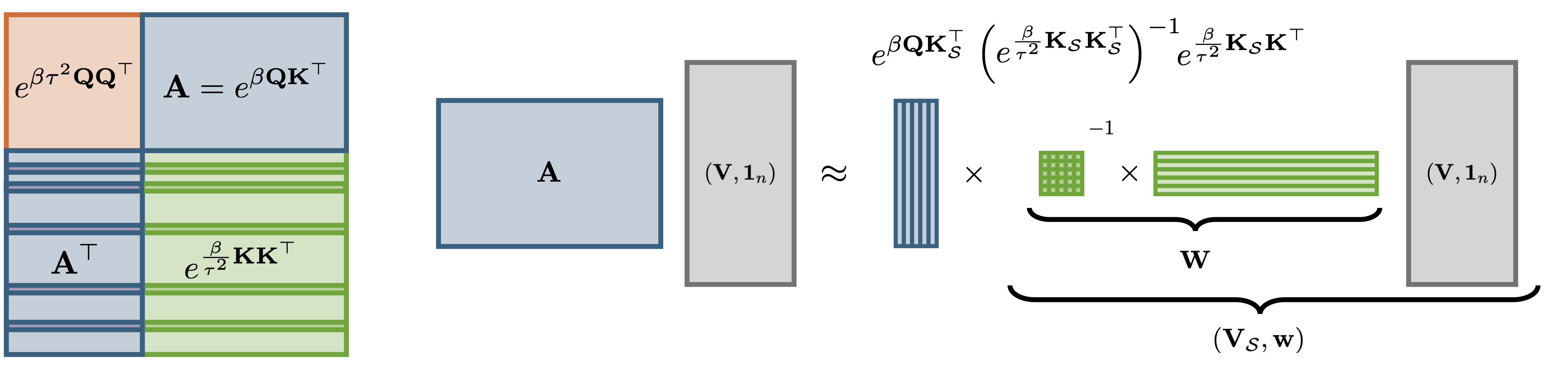
Near-linear softmax attention in theory and practice via weighted coresets
We introduce a principled online method to approximate the softmax attention mechanism from a coreset of reweighted keys and values. This enables accurate inference for long context tasks at a fraction of the computational cost and memory footprint.
Read more →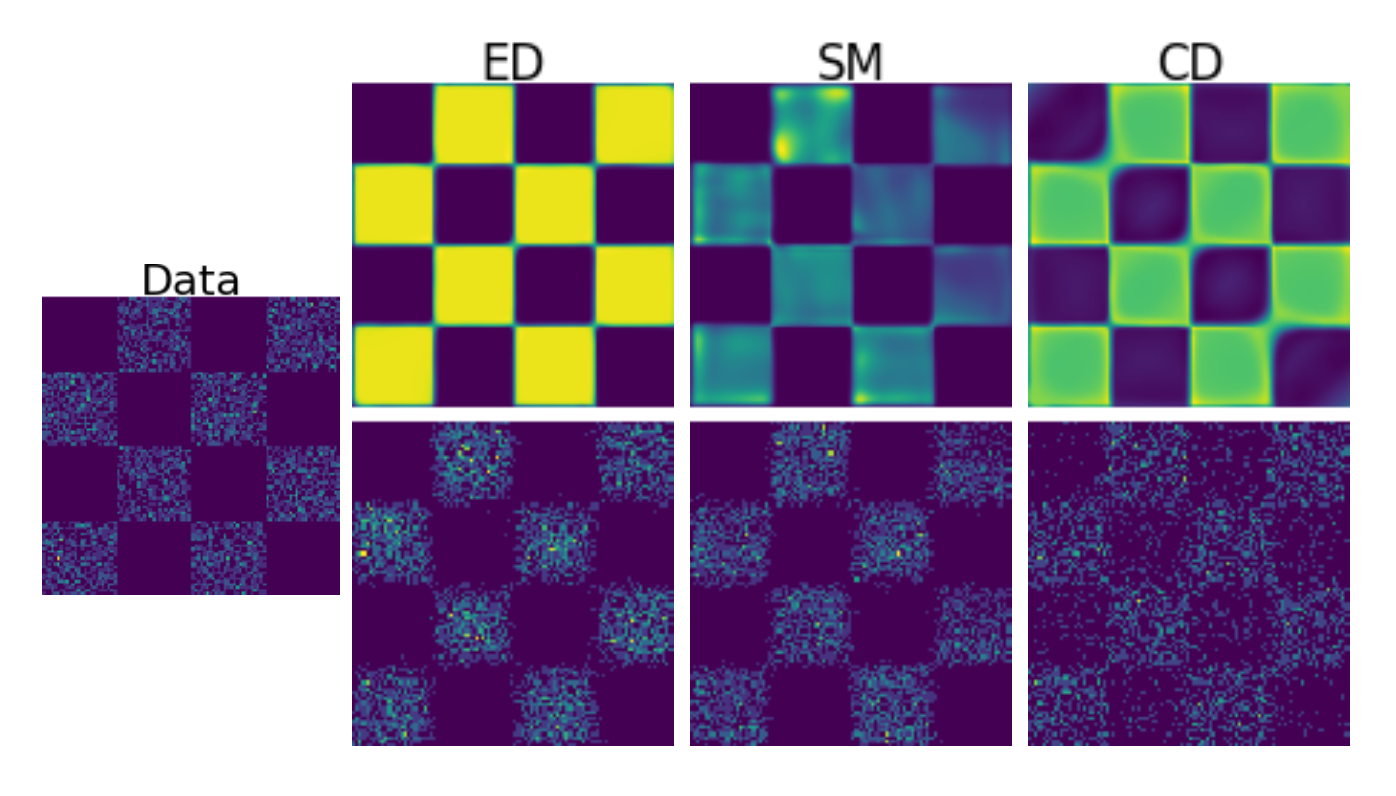
Simulation-free training of energy-based models
We propose Energy Discrepancy (ED), a new training methodology for energy-based models that avoids sampling-based methods like contrastive divergence while yielding stronger estimators than score-based methods.
Read more →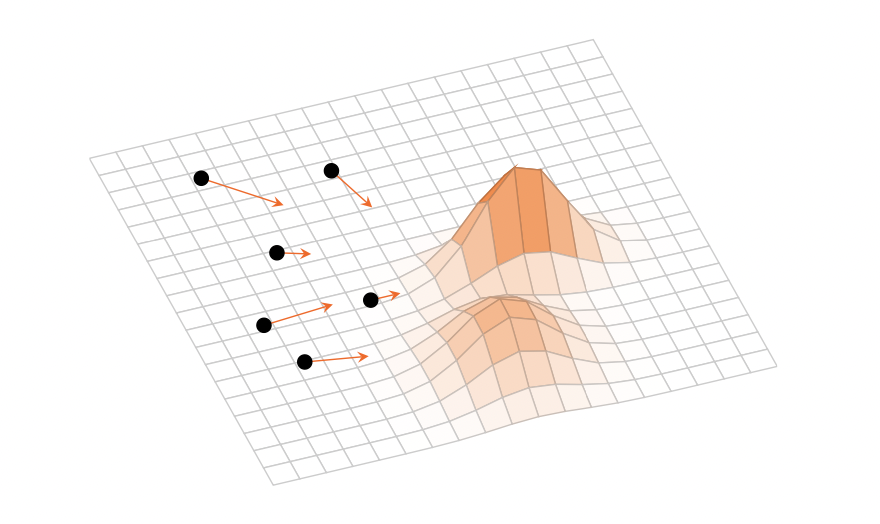
Variational Inference as a Gradient Flow in a Kernelised Wasserstein Geometry
For my Master's thesis, I formulated variational inference training dynamics as a gradient flow in a kernelised Wasserstein geometry, connecting Stein geometries with black-box variational inference.
Read more →